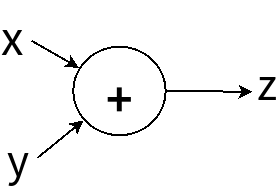
到今,咱已經共所有倒退攄所需要的倒退攄攏搜揣出來,這馬是時機來共伊佮做伙。咱先來看伊的圖:
咱來斟酌解說一个:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 開始攢好勢
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 共伊一棧一棧疊khi
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
向前行
主程式是 gradient(),一開始就呼 (khoo/call) self.loss(x, t),
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
這 loss() 就是共向前行(Forward propagation),softmax 和 error function 一擺做到底。
# x:入力データ, t:教師データ
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
loss() 分兩步: predict() 佮 lastLayer.forward(),也就是共上尾彼 SoftmaxWithLoss() 另外做。
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
predict() 嘛是有影簡單。一个 for 箍輾,照步來,去呼 layers 內面,逐棧的 forward() 函式。照頂懸 __init__() 所指定,就是照 Affine1, ReLU1, Affine2,一个一个呼伊的 forward(),共逐棧的輸出,成做會一棧的輸入。
倒退攄
佇 gradient() 內底,dout = 1 做參數開始,先呼上尾棧 lastLayer 的 backward()。紲落來這幾逝嘛是用
OrderedDict 的奇巧:
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
因為伊是照順序,我共伊的值捎出來,共伊顛倒反 (layers.revers()),閣用 for 箍輾,伊就是倒退攄囉。
結束了後,咱欲愛的 W1 和 W2 的改變,是囥佇 Affine layer 內底 (參考
layers.py 的 Affine Clase), 所以愛共伊掠出來:
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
擲轉去。
grad = network.gradient(x_batch, t_batch)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
紲落來才閣進行下一擺的訓練。
uì
20181028 講到今嘛年外,講甲落落長,伊上重要的觀念就是共正港的數學微分,伊的運算方式,改用倒退攄的方法。倒退攄,其實就是共微分个運算拍破,分解做上基本的神經元有法度算。按呢生會使予會算數速度加有夠緊,按呢才有實用的價值。
寫到遮,應該共神經網路上基本的原理講到一个崁站矣。這个系列嘛欲踮遮到煞鼓矣。這本書:
後半段閣有袂少內容。毋過,完全共人用心血寫落來的書囥佇網路頂予人免費看,按呢嘛無好。向望逐家若是有興趣,會當去共伊交關一咧。
因為是利用做工課掠外,有閒的時間才寫,有當時閣會懶屍,所以進度真慢。總是,佇寫的時陣,才會了解台語欲寫專業的物件,會拄著啥乜困難,解決的方向是佗一爿? 加一个行業有人用台語寫作,就加一个行業的專有名詞會生--出來。各行各業攏有人用台語寫,台語才會健康生湠落去。特別是上新个智識,咱莫共家己母語限制佇厝內,抑是懷舊爾爾。